
por Felipe Pait
“Qualquer tecnologia suficientemente avançada é indistinguível da magia”, escreveu o escritor de ficção científica inglês Arthur C. Clarke. Avanços recentes da inteligência artificial, do aprendizado por máquinas, e da ciência dos dados podem parecer mágicos, mas ficam menos misteriosos se entendermos os conceitos básicos. Para isso vamos passar por cima de detalhes técnicos que caem nas provas de estatística da faculdade mas não bastam para interpretar corretamente o resultados das análises.
Duas ferramentas fundamentais da ciência dos dados são a regressão e a classificação, ilustradas na figura abaixo. O objetivo da regressão linear é encontrar a linha reta que passa mais próxima de um conjunto de pares de medidas. No gráfico à esquerda, pode-se perceber uma tendência de crescimento de uma medida com a outra, embora os pontos não estejam perfeitamente alinhados. Eles poderiam representar, por exemplo, notas de diversos estudantes num exame vestibular no eixo vertical, e a renda familiar no eixo horizontal. A regressão nos permite extrapolar os resultados das medidas disponíveis, e estimar o resultado de experimentos não realizados. Em outras palavras, conhecendo a renda familiar de um estudante, podemos esperar que sua nota se encontre próxima à linha reta traçada.
Já a classificação linear busca uma linha reta capaz de separar, da melhor forma possível, as medidas em 2 conjuntos. No gráfico à direita os pontos representariam as notas dos mesmos estudantes nas provas de física na ordenada (vertical), e de biologia na abscissa (horizontal). A classificação dos dados permite formular explicações complexas, sem assumir que todos os indivíduos de um grupo têm o mesmo comportamento. Nesse exemplo, não temos informação prévia sobre quais medidas pertencem a qual dos grupos. Sendo gráficos meramente hipotéticos, podemos deixar a cargo da imaginação os mecanismos que produzem os padrões ilustrados.

É visível que não existe uma reta que passe exatamente por todos os pontos, nem uma reta que separe pontos de forma inequívoca. A matemática que embasa a ciência dos dados consiste em definir os critérios pelos quais a reta da regressão é a “melhor aproximação” para os dados à esquerda, e a reta separatriz a “melhor classificação” dos dados à direita, para em seguida calcular as retas que atendem os critérios. Vamos deixar a discussão técnica para uma leitura ou releitura dos livros didáticos, e nos concentrar nas semelhanças entre os procedimentos. Por que usar regressão e classificação lineares?
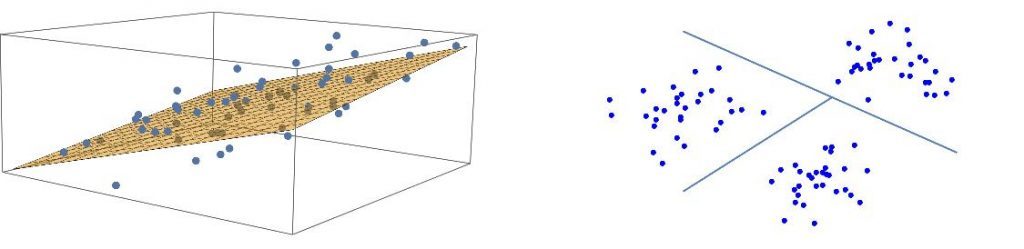
As vantagens e desvantagens decorrem da simplicidade, que é visualmente evidente. Uma reta é determinada por apenas 2 parâmetros – na geometria euclidiana, por 2 pontos passa uma e apenas uma reta. Desta forma os cálculos necessários para a análise se resumem a encontrar posição e inclinação da reta, não sendo complicados nem sujeitos a grandes erros. Passando do plano para o espaço tridimensional e para espaços de dimensão maior – que são de visualização difícil senão impossível, mas não oferecem maiores dificuldades matemáticas para a análise linear – os procedimentos podem ser generalizados para casos em que temos diversas variáveis. Na figura seguinte ilustramos a regressão com 3 variáveis, e a classificação, esta ainda no plano, em 3 grupos.
Uma simplificação ainda maior ocorre quando só queremos saber se uma variável aumenta ou diminui com a outra, sem necessidade de estimar a inclinação da reta de regressão. Por exemplo, o médico apenas precisa saber se um medicamento tende a melhorar ou piorar o estado de saúde do paciente. O resultado importante da análise matemática de regressão é simplesmente verificar se a saúde do paciente está relacionada de forma positiva com a dose do novo remédio. As ferramentas da estatística são capazes de indicar qual a confiança que se pode ter na correlação detectada, analisando dados de pacientes que já usaram o tal remédio, em geral em estudos controlados e que seguem normas rígidas. Uma alta probabilidade de eficácia do tratamento justifica sua adoção para a população em geral, contanto que haja algum efeito positivo mensurável.
Nesses casos, as análises estatísticas costumam apresentar apenas o valor-p (também chamado de nível descritivo ou probabilidade de significância) da hipótese de que uma variável influencia a outra, omitindo a intensidade da influência. Hoje em dia, com a abundância de dados e facilidade de tratamento numérico, esse é um caminho perigoso. No mundo de “big data”, um pesquisador criativo e determinado encontra, mais cedo ou mais tarde, alguma correlação com significância estatística. Será uma dependência real entre as variáveis, ou apenas um erro chamado “do Tipo II”, que consiste em aceitar como verdadeira uma hipótese errônea? Um erro, ainda que improvável, vai acabar aparecendo depois de muitas tentativas. A busca exaustiva de correlações entre combinações de dados, quando feita deliberadamente ou sem a cautela de evitar falsos positivos, recebe o nome pejorativo de “p-hacking”.
Os modelos lineares completos, incluindo os coeficientes, ou seja, a intensidade da correlação, o quanto uma coisa impacta na outra, oferecem subsídios adicionais para compreensão dos mecanismos envolvidos. Quando apenas os valores-p são disponíveis, a pesquisa deve ser replicada com novos dados – procedimento dispendioso nas ciências experimentais, e em geral impossível nas ciências humanas. Sem confirmação independente, um estudo que apenas indique a existência de interdependência entre variáveis deve ser encarado como um exercício escolar, e não como suporte para a formulação de condutas médicas ou políticas públicas. E nunca podemos esquecer que correlação não implica causalidade!
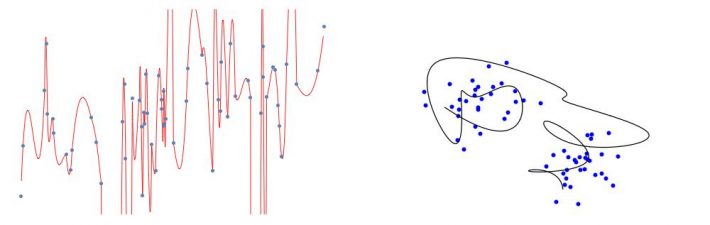
As limitações da análise linear decorrem também da simplicidade do procedimento. O fato é que apenas os fenômenos quantificáveis mais bem estudados seguem leis lineares. Para descrever novas leis das ciências, é necessário usar funções e classificações mais flexíveis e sofisticadas. Curvas e superfícies matematicamente complexas são em princípio capazes de explicar ou separar quaisquer conjuntos de dados. Podemos talvez dizer que grande parte da moderna teoria do aprendizado por máquina e da inteligência artificial é dedicada aos seguintes problemas:
Escolher funções matemáticas para extrapolar e classificar dados quantitativos;
Desenvolver métodos de cálculo dos parâmetros dessas funções matemáticas a partir das observações; e
Determinar com confiança que os resultados obtidos refletem leis que governam o comportamento dos fenômenos observados, e não são apenas artefatos da escolha das funções excessivamente sofisticadas.
O que acontece com os estudos estatísticos no contexto atual, onde temos à disposição não poucos dados a partir dos quais tirar conclusões sobre como as coisas se relacionam, mas sim uma abundância de dados impressionante, acoplada a capacidade de cálculos gigantesca comparadas com o que tínhamos meio século atrás, na época dos cartões perfurados e da régua de cálculo? Quais os cuidados que temos que tomar, para não sairmos por aí declarando relações entre o uso de chapéu e o resultado das eleições? Como evitar explicações “perfeitas” ou classificações fantásticas como na terceira figura? Vamos voltar a essas questões em outra ocasião.



